Hvad er webskrabning? Sådan samles data fra websteder
Reklame
Webskrapere indsamler automatisk oplysninger og data, der normalt kun er tilgængelige ved at besøge et websted i en browser. Ved at gøre dette autonomt åbner scrapning af webe en verden af muligheder inden for data mining, dataanalyse, statistisk analyse og meget mere.
Hvorfor webskrapning er nyttigt
Vi lever i en dag og alder, hvor information er lettere tilgængelig end nogen anden tid. Den infrastruktur, der er brugt til at levere netop disse ord, du læser, er en ledning til mere viden, mening og nyheder, end der nogensinde har været tilgængelig for mennesker i folks historie.
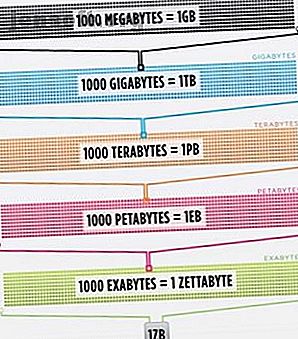
Så meget så faktisk, at den smarteste persons hjerne, forbedret til 100% effektivitet (nogen burde lave en film om det), stadig ikke ville være i stand til at besidde en 1/1000-del af de data, der er gemt på internettet alene i USA .
Cisco vurderede i 2016, at trafikken på internettet overskred en zettabyte, der er 1.000.000.000.000.000.000.000 byte, eller en sextillion byte (gå videre, fnise på sextillion). En zettabyte er omkring fire tusind år med streaming af Netflix. Det ville svare til, hvis du, uhyggelig læser, skulle streame kontoret fra start til slut uden at stoppe 500.000 gange.

Alle disse data og oplysninger er meget skræmmende. Ikke det hele er rigtigt. Ikke meget af det er relevant for hverdagen, men flere og flere enheder leverer denne information fra servere over hele verden lige til vores øjne og i vores hjerner.
Da vores øjne og hjerner ikke rigtig kan håndtere alle disse oplysninger, er skrabning på nettet dukket op som en nyttig metode til indsamling af data programmatisk fra internettet. Webskrapning er det abstrakte udtryk til at definere handlingen med at udtrække data fra websteder for at gemme det lokalt.
Tænk på en type data, og du kan sandsynligvis indsamle dem ved at skrabe internettet. Fast ejendomslister, sportsdata, e-mail-adresser for virksomheder i dit område og endda tekst fra din yndlingsartist kan alle søges og gemmes ved at skrive et lille script.
Hvordan får en browser webdata?
For at forstå webskrabere skal vi forstå, hvordan internettet fungerer først. For at komme til dette websted, skrev du enten “makeuseof.com” i din webbrowser, eller du klikkede på et link fra en anden webside (fortæl os hvor vi seriøst ønsker at vide). Uanset hvad, de næste par trin er de samme.
Først tager din browser den URL, du indtastede eller klikkede på (Pro-tip: hold musepekeren over linket for at se URL-adressen i bunden af din browser, før du klikker på den for at undgå at blive punk'd) og danne en "anmodning" om at sende til en server. Serveren behandler derefter anmodningen og sender et svar tilbage.
Serverens svar indeholder HTML, JavaScript, CSS, JSON og andre data, der er nødvendige for at give din webbrowser mulighed for at danne en webside, så du kan se dem.
Inspektion af webelementer
Moderne browsere tillader os nogle detaljer vedrørende denne proces. I Google Chrome på Windows kan du trykke på Ctrl + Shift + I eller højreklikke og vælge Inspekter . Vinduet viser derefter en skærm, der ligner det følgende.

En fanebladeliste med indstillinger linjer toppen af vinduet. Af interesse lige nu er fanen Netværk . Dette giver detaljer om HTTP-trafikken som vist nedenfor.

I nederste højre hjørne ser vi oplysninger om HTTP-anmodningen. URL-adressen er, hvad vi forventer, og “metoden” er en HTTP “GET” -anmodning. Statuskoden fra svaret er angivet som 200, hvilket betyder, at serveren så anmodningen som gyldig.
Under statuskoden ligger fjernadressen, som er den offentligt IP-adresse på makeuseof.com-serveren. Klienten får denne adresse via DNS-protokollen Hvorfor ændring af DNS-indstillinger øger din internethastighed Hvorfor ændring af DNS-indstillinger øger din internethastighed Ændring af dine DNS-indstillinger er en af de mindre justeringer, der kan have store afkast på de daglige internethastigheder. Læs mere .
Det næste afsnit viser detaljer om svaret. Svarhovedet indeholder ikke kun statuskoden, men også den type data eller indhold, som svaret indeholder. I dette tilfælde ser vi på “text / html” med en standardkodning. Dette fortæller os, at svaret bogstaveligt talt er HTML-koden, der skal gengives webstedet.

Andre typer svar
Derudover kan servere returnere dataobjekter som svar på en GET-anmodning i stedet for blot HTML, som websiden skal gengives til. Et websteds applikationsprogrammeringsgrænseflade (eller API) Hvad er API'er, og hvordan ændrer åbne API'er Internettet Hvad er API'er, og hvordan er åbne API'er ændrer Internettet Har du nogensinde spekuleret på, hvordan programmer på din computer og de websteder, du besøger "talk" til hinanden? Læs mere bruger typisk denne type udveksling.
Gennemse fanen Netværk som vist ovenfor, kan du se, om der er denne type udveksling. Ved undersøgelse af CrossFit Open Leaderboard vises anmodningen om at udfylde tabellen med data.

Ved at klikke over til svaret vises JSON-dataene i stedet for HTML-koden til gengivelse af webstedet. Data i JSON er en række etiketter og værdier i en lagvis, skitseret liste.

At manuelt analysere HTML-kode eller gå gennem tusinder af nøgle- / værdipar JSON er meget som at læse Matrix. Ved første øjekast ser det ud som snavs. Der kan være for meget information til manuelt at afkode den.
Webskrabere til redning!
Før du beder om den blå pille for at få pokker ud herfra, skal du vide, at vi ikke er nødt til manuelt at afkode HTML-kode! Uvidenhed er ikke lykke, og denne bøf er lækker.
En webskraber kan udføre disse vanskelige opgaver for dig. Scrapestack API gør det nemt at skrabe websteder til data Scrapestack API gør det nemt at skrabe websteder til data Leder du efter en kraftfuld og overkommelig webskraber? Scrapestack API er gratis at starte og tilbyder mange praktiske værktøjer. Læs mere . Skrapningsrammer er tilgængelige på Python, JavaScript, Node og andre sprog. En af de nemmeste måder at begynde skrabning er ved hjælp af Python og smukke suppe.
Skrabe et websted med Python
At komme i gang tager kun et par kodelinjer, så længe du har Python og BeautifulSoup installeret. Her er et lille script for at hente et websteds kilde og lade BeautifulSoup evaluere det.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Vi sender ganske enkelt en GET-anmodning til en URL og placerer derefter svaret i et objekt. Udskrivning af objektet viser HTML-kildekoden til URL'en. Processen er ligesom hvis vi manuelt gik til webstedet og klikker på Vis kilde .
Specifikt er dette et websted, der posterer træning i CrossFit-stil hver dag, men kun en pr. Dag. Vi kan opbygge vores skraber for at få træningen hver dag og derefter føje den til en samlet liste med træning. I det væsentlige kan vi oprette en tekstbaseret historisk database med træning, som vi let kan søge igennem.
Magien med BeaufiulSoup er muligheden for at søge gennem al HTML-koden ved hjælp af den indbyggede findAll () -funktion. I dette specifikke tilfælde bruger webstedet flere "sqs-block-content" -koder. Derfor skal scriptet gå igennem alle disse tags og finde det, der er interessant for os.
Derudover er der et antal
tags i sektionen. Scriptet kan tilføje al teksten fra hver af disse tags til en lokal variabel. For at gøre dette skal du tilføje en enkel løkke til scriptet:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Sådan! En webskraber er født.
Skaler op Skrabning
Der findes to stier for at komme videre.
En måde at udforske webskraber er at bruge allerede opbyggede værktøjer. Web Skraber (godt navn!) Har 200.000 brugere og er let at bruge. Parse Hub giver også brugere mulighed for at eksportere skrapede data til Excel og Google Sheets.
Derudover leverer Web Scraper et Chrome-plug-in, der hjælper med at visualisere, hvordan et websted er bygget. Bedst af alt er at dømme efter navn OctoParse, en kraftig skraber med en intuitiv interface.
Endelig, nu hvor du kender baggrunden for webskrabning, hæver din egen lille webskraber for at være i stand til at gennemgå og køre Sådan oprettes en grundlæggende webcrawler til at trække oplysninger fra et websted Sådan oprettes en grundlæggende webcrawler til at trække oplysninger fra en Websted Har du nogensinde ønsket at indhente oplysninger fra et websted? Du kan skrive en crawler for at navigere på webstedet og udtrække lige det, du har brug for. Læs mere på egen hånd er en sjov bestræbelse.
Udforsk mere om: Python, Webskrapning.

